Margaret is 68. She walks slowly to the local health clinic because the hill leaves her breathless. At night she props herself on two pillows so she can breathe. She tells herself that she is just getting older.
At her checkup, the nurse runs a 12-lead ECG. The paper prints in ten seconds. The doctor glances at the tracing, sees no clear arrhythmia, notes her blood pressure is high, and adjusts her medication for ankle swelling. No one says heart failure.
Six months later Margaret is in the emergency department, lungs full of fluid, unable to lie flat. The echo finally shows the truth. Her heart is stiff. It pumps a normal amount of blood with each beat, but it cannot relax to fill properly. She has heart failure with preserved ejection fraction, the type that is missed most often.
The authors of the npj Digital Medicine study consisting of Elias Stenhede , Jesper Ravn, Henrik Schirmer, and Arian Ranjbar, begin with exactly this problem. They write that the diagnosis of heart failure is resource intensive, leading to severe underdiagnosis. Diagnosis usually depends on symptoms, an exam, labs, and an echocardiogram. A lot of patients stall before the last step.
Their proposal is simple. What if Margaret's first ECG already contained the pattern, and we just needed better eyes to see it?
The Norwegian team trained an open-source deep learning model to do that reading. They used approximately 284,161 ECGs, then tested it prospectively on 43,109 patients and again externally on 161,208 patients in the United States. The goal was to get more diagnostic value from the ECG we already use by enabling it to recognize and detect early signals of heart failure.
Why heart failure hides in plain sight
Heart failure does not mean the heart has stopped. It means the heart cannot keep up with what the body asks for. Sometimes it is too weak to squeeze. Sometimes it is too stiff to fill. Both feel the same to the patient. Shortness of breath, fatigue, swollen ankles.
Doctors divide this into two main patterns. The first is heart failure with reduced ejection fraction, or HFrEF. Ejection fraction is the percentage of blood the left ventricle pushes out with each beat. A normal value is around 50 to 70 percent. In HFrEF it is usually below 40 percent. The heart is a weak pump.
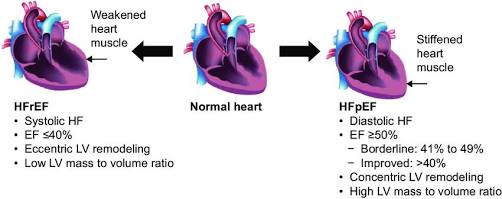
The visual difference between HFrEF and HFpEF. Source researchGate
The second is heart failure with preserved ejection fraction, or HFpEF. The pump strength looks normal on an echo, but the muscle is stiff. It cannot relax properly, so pressure builds up in the lungs and veins. The paper notes that about half of all people with heart failure fall into this group, and they are more often older, female, and living with other conditions like hypertension and diabetes.
The problem is that confirming either type is not simply a question of past history or family genetics. Medical guidelines lean on symptoms, physical exam, a blood test called NT-proBNP , and an echocardiogram. That last step needs equipment, a trained sonographer, and a cardiologist to read it. In busy clinics, any link in that chain can break. The result is what the authors describe at the outset as a "resource intensive diagnosis that leads to severe underdiagnosis, especially for HFpEF".
That is why an ECG is tempting. It is already done, it is cheap, and it is digital. The question is whether the subtle electrical changes of a tired or stiff heart are actually in the tracing.
For home monitoring, clinicians often recommend FDA-cleared personal ECGs like KardiaMobile or an upper-arm blood pressure monitor .
The problem was the labels
Traditional medical AI models are trained much like a student memorizing flashcards: they are presented with an ECG paired with a known outcome. For heart failure detection, this 'ground truth' is typically derived from electronic health records using ICD-10 diagnostic codes.
The Norwegian team points out the flaw in that method. Those codes have limited validity. A busy clinician may enter the code when heart failure is suspected but not confirmed. Another may treat heart failure but never code it. If you train an AI on noisy answers, the AI learns the noise.
Their fix was pragmatic labelling. Instead of trusting the code alone, they combined it with a blood test that reflects cardiac stress, NT-proBNP. This is the same biomarker clinicians use to rule heart failure in or out. The team noted that NT-proBNP was exactly the right biomarker to pair with ICD codes because it responds directly to myocardial wall stress (stretching), making it an excellent "biological check" for both weak hearts (HFrEF) and stiff hearts (HFpEF). By pairing the two sources during training, they could estimate the likelihood that a patient truly had the syndrome.
They built three versions of the truth to train on.
First, the standard approach, code only. Second, code plus age-adjusted NT-proBNP thresholds. Third, a strict definition that kept only high-confidence cases, a code plus NT-proBNP above 1,000 ng/L for positives, and no code plus NT-proBNP below 125 ng/L for negatives. Patients in the middle were left out of training for that version.
Cleaning the labels changed what the model learned. When tested prospectively on 43,109 patients, the code-only model reached an AUC of 0.84. With age-adjusted NT-proBNP, performance rose to 0.92. With the strict definition, it reached 0.96. The same pattern held in the external MIMIC-IV validation of 161,208 patients, with AUCs of 0.87, 0.90, and 0.96.
In short, better teaching data made a better reader. The ECG did not change. What changed was the definition of heart failure used for training.
Getting to the Truth
Teaching an AI to spot heart failure starts with what will be called 'the truth'.
In most hospital datasets, the truth is an ICD-10 code. If the chart says heart failure, the ECG paired with that visit gets labeled positive. That is convenient, because codes are already in the record. It is also noisy. Codes are written for billing; they can be added late, and they are often missing when the diagnosis is uncertain. The authors note that this limited validity makes it hard to train a model directly from codes alone.
That noise has pushed earlier ECG work toward a narrower target. Instead of the whole syndrome, many models were trained to predict a low ejection fraction (EF), because EF is a clean number from an echo report. That works well for HFrEF, the weak pump, but it teaches the model to ignore HFpEF, the stiff heart that looks normal on a squeeze test. In practice, about half of patients get left out.
The Norwegian team kept the broader target, heart failure as clinicians see it, and cleaned the labels instead of shrinking the question. They used pragmatic labelling, which pairs the ICD code with the NT-proBNP value drawn near the ECG. NT-proBNP rises when the heart muscle is stretched, so it adds a biological check to the administrative code.
They tested three definitions. The first used the code alone. The second required the code plus an age-adjusted NT-proBNP threshold. The third was the strictest, counting a case as positive only when the code was present and NT-proBNP was above 1000 ng per liter, and as negative only when there was no code and NT-proBNP was below 125. Patients between those values were excluded from training for that version.
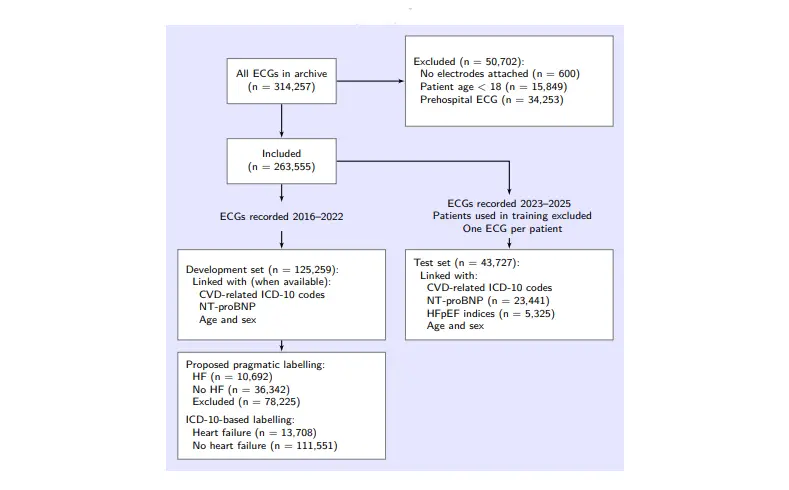
Flowchart of the ECGs used in model development and testing. The labelling of each ECG is determined by whether the patient receives an HF diagnosis within 60 days of ECG recording
The beauty of this approach is that it requires no new tests; both the diagnostic codes and the blood markers are already sitting in routine clinical records. By sharpening the definition of "truth," the training data became smaller but far more precise. The model wasn’t just trained to spot a low EF; it learned to decode the actual electrical footprint of heart failure itself.
How well it worked on patients it had never met
The team did not test the model on the same hospital data it learned from. They ran a prospective validation on 43,109 patients from Akershus University Hospital in Norway. Each patient contributed their first ECG during the study window, and the model generated a single risk score from that tracing alone.
Performance depended on how clean the reference label was. With the standard code-only definition, the AUC was 0.84. When the reference combined the code with age-adjusted NT-proBNP, the AUC rose to 0.92. With the strict NT-proBNP cutoffs of 125 and 1000, the AUC reached 0.96.
Those numbers held up outside Norway. In the MIMIC-IV ECG set from Beth Israel Deaconess Medical Center, 161,208 patients were scored the same way. The model achieved AUCs of 0.87, 0.90, and 0.96 across the three definitions. They noted that "The consistency across two health systems suggests the model is picking up physiology, not local coding habits".
The authors also checked what the score meant clinically. Patients the model called high risk were more likely to have abnormal diastolic function on echo and higher H2FPEF scores, the clinical tool used to estimate probability of HFpEF. Importantly, the signal was present in both HFrEF and HFpEF groups. The model was not just a low EF detector in disguise.
Performance was strongest in younger patients and decreased with age, which fits the reality that older patients accumulate more comorbidities and noisier labels. Even so, discrimination remained solid across age and sex strata.
In plain terms, a ten second ECG produced a risk score that tracked with the biology of heart failure, in two countries, without seeing an echo.
What the model actually is
The model is a residual neural network trained on raw ECG voltage, not on measurements a cardiologist would write down. Each input is a standard 12-lead tracing, ten seconds long, sampled at 500 Hz. There is no manual feature extraction. The network learns its own patterns from the waveforms.
That choice matters because unlike human readers who look for familiar landmarks, like QRS width or ST changes, a deep neural network can combine thousands of subtle shifts across leads and time points that do not have names. The authors did not try to force the model to explain itself with handcrafted features. They let the data shape the filters.
Training used approximately 284,161 ECGs from Norway, paired with the three versions of pragmatic labels described earlier. Validation was kept strictly separate, both in time and in place, which is why the prospective Norwegian cohort and the US MIMIC-IV set are important.
The team released the full pipeline as open source. Code, weights, and inference scripts are on GitHub , so other hospitals can run the same model on their own ECGs without sending data anywhere. Inference is fast. A single ECG scores in milliseconds on a standard GPU, and in well under a second on a CPU.
Open sourcing does two things. It lets independent groups check the claims on their own patients, and it lowers the barrier for clinics that already store digital ECGs but do not have an echo lab on site.
Why this changes the game for primary care
The model was trying to spot the clinical syndrome of heart failure from a ten second ECG, across the full ejection fraction spectrum.
In that prospective Norwegian test set, it reached an AUC of 0.84 for hospital diagnosed heart failure, regardless of EF or NT-proBNP level. In patients who had NT-proBNP measured, the ECG score outperformed NT-proBNP itself.
When they looked at the subset who had an echo within 14 days, the pattern split exactly as you would hope. For HFrEF, the weak pump, AUC was 0.92. For HFpEF, the stiff heart, AUC ranged from 0.68 to 0.89 depending on definition. That range reflects how slippery HFpEF is to label, not a flaw in the ECG. Even at the low end, the model is picking up signal where earlier AI work mostly gave up, because those models were trained only to predict low EF.
The most telling experiment was tiny but clinical. The team pulled 60 patients with EF above 50 percent, no heart failure diagnosis, and a normal NT-proBNP under 125. These are the patients who usually get sent home. The model flagged 30 as high risk and 30 as low risk. On blinded chart review, 24 of the 30 high risk patients met HFpEF criteria, while 27 of the 30 low risk patients did not.
Because the input is a digital ECG that already exists in most clinics, the barrier is software, not hardware. No extra blood draw, no referral delay. The authors frame it as a screening marker to identify who may benefit from further evaluation, not as a replacement for echo.
What the study does not claim, and where it fits
This model was trained and tested to detect hospital-admitted heart failure. The training labels came from a pragmatic pairing of ICD-10 codes with NT-proBNP, and the team deliberately excluded the gray zone where NT-proBNP sits between 125 and 1000 ng per liter. In the development set that meant leaving out about 83,000 ECGs to keep the teaching set cleaner.
That choice has tradeoffs. You get a sharper signal, but you also train the model on clearer cases. Performance reflects that. In the prospective test of 43,000 patients, the overall AUC was 0.84 for hospital-diagnosed heart failure, and the model outperformed NT-proBNP when both were available.
When you split by phenotype, the model is strongest where medicine already has good tools. For HFrEF, AUC was 0.92. For HFpEF, AUC ranged from 0.68 to 0.89 depending on how strictly you define the condition. That spread is important. HFpEF is a clinical diagnosis with no single gold standard, so any AI score will wobble with the definition you choose.
The authors also show alignment with existing clinical risk tools. Model-predicted risk rose with the H2FPEF score and added stratification within each H2FPEF category. That suggests the ECG is not replacing clinical judgment, it is giving you an earlier, objective nudge.
The small retrospective look at 60 low-biomarker, preserved-EF patients is where the promise sharpens. Among patients with normal NT-proBNP and no coded diagnosis, the model flagged 30 as high risk. On review, 24 of those 30 met HFpEF criteria, while 27 of the 30 low-risk patients did not. It is a tiny sample, but it points to the exact gap Margaret fell into, patients who look fine on paper until you dig deeper.
The authors close by positioning the tool as an accessible marker for primary care, a way to screen with the ECG you already have and triage to echo, not a standalone diagnostic.
The bottom line
Margaret's story is about a test that was not designed to answer the question we were asking.
The Norwegian team showed you can change that without changing the hardware. By pairing routine ICD codes with NT-proBNP to clean the teaching labels, and by training on raw 12-lead voltage from more than 160,000 ECGs, they built a model that learns the electrical signature of heart failure as a syndrome, not just a low ejection fraction. Their aim, stated plainly, was to show that explicit echocardiographic labeling is not necessary for this task.
In prospective testing on 43,000 new patients, the model reached an AUC of 0.84 for hospital-diagnosed heart failure and outperformed NT-proBNP head to head. It detected HFrEF with an AUC of 0.92, and it detected HFpEF with AUCs from 0.68 to 0.89 depending on definition, the first time an ECG model has shown consistent signal across the full spectrum in a large prospective cohort.
That matters because HFpEF makes up about half of heart failure and is exactly where current pathways stall. A ten second ECG that flags risk at the point of first contact could shorten the long diagnostic odyssey, prioritize echo for those who need it most, and give primary care a tool that works where NT-proBNP is normal or unavailable.
The work is not a finished product. It was developed on hospital data, it excluded the NT-proBNP gray zone during training, and HFpEF remains hard to define. But it proves a principle. When you teach the model with better labels, the old ECG starts to see what clinicians feel at the bedside.
For patients like Margaret, that could mean the difference between years of breathlessness and starting SGLT2 inhibitors, diuretics, and structured follow up while the heart still has reserve. Teaching an old test a new skill will not solve heart failure, but it might help us detect it on time.
Read the full paper here: Heart failure detection in electrocardiograms using Artificial Intelligence and pragmatic labelling







